Hopefully, you are using a database (of some description) to hold your data. Perhaps you have some way of looking up in your database the provenance of each data item, i.e., which question (or questions) did this come from. Other ways of managing this problem are in a panel study where it is common to keep the name of the data item the same, but prepended with a wave identifier. In either case having a lookup of comparable variables is an essential starting point.
Normally, users of the data will not access your data directly, but in a statistical package such as SPSS or Stata and this is what you will want to document.
There are several tools available to document the dataset(s) in the current version of DDI-L -- StatTransfer, SledgeHammer and Colectica. They do this by extracting the rich metadata that already exists in your statistical dataset, such as the variable labels, the code lists, and other information such as the number of cases, and optionally the statistics (mean, max, frequency, etc.) for the variables themselves and creating a DDI-L file in a standardized format that can be used across all of your data.
DDI-L provides several mechanisms for grouping variables that are comparable. Fuller discussion of this is in the DDI Best Practice series "Enabling Longitudinal Data Comparison Using DDI" [http://dx.doi.org/10.3886/DDILongitudinal02], although you should be aware that this paper refers to a previous iteration of DDI-L (version 3.1).
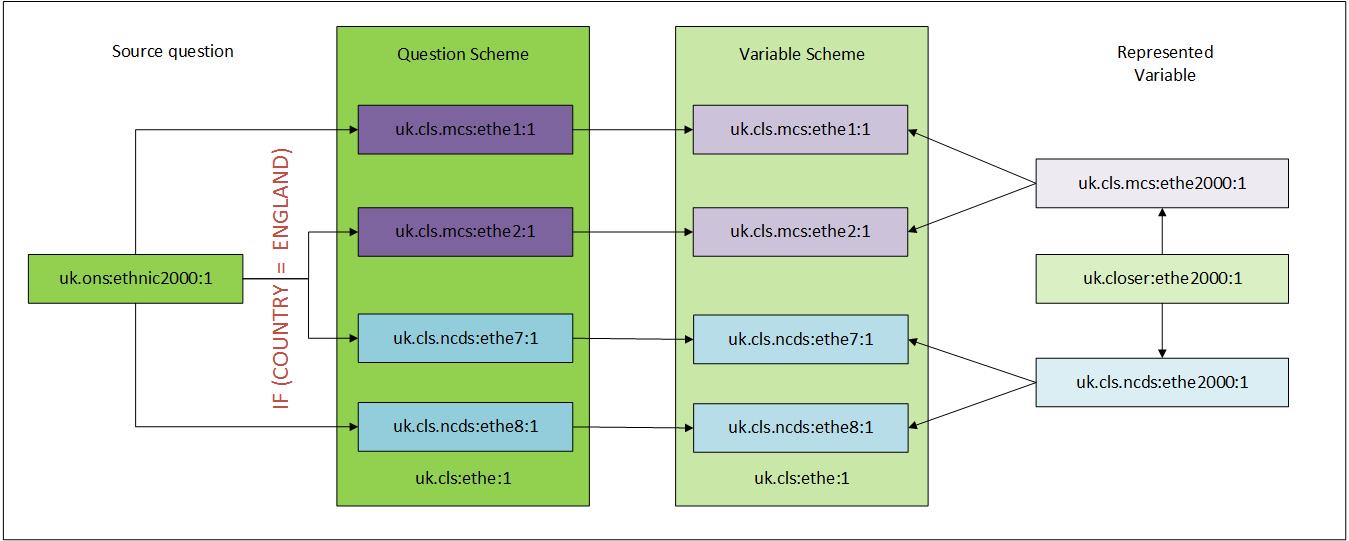
The following diagram illustrates a simplified version of the connection between a source question, the question used in a set of surveys, the variables and the mapping between them, The Design/Document Survey Questionnaires from Scratch section shows how you can document the questions (which are held in a QuestionScheme).
In this example, we have incorporated the name of the question and variable into the DDI URN which uniquely identifies the question or variable with DDI-L. This is composed of an Agency (the owner of the object) and identifier for the object and a version. The same question was asked at two different sweeps of two studies, the study is indicated by the DDI Agency uk.cls.mcs and uk.cls.ncds and ethe1, ethe2, ethe7 and ethe8 are the identifiers for the questions,
A represented variable is a mechanism to allow a user to create a ‘virtual variable’ that we can use to link variables together and allows us to document their similarity.
In this illustration, a represented variable has been created within each study, uk.cls.mcs.ethe2000 and uk.cls.ncds.ethe2000. An additional represented variable has also been created that references them and potentially other occurrences of this represented variable.
Tools
The above can be accomplished using traditional XML tools such as XSLT or using Colectica Designer and Repository.